Hardware Designs for DNN Inference
Due to the high computational complexity of DNN inference, there has been intense effort to design hardware that performs the computation efficiently. On the commercial side, we have Google TPUs[1] which can be used in the Google Cloud and specialization in NVIDIA GPUs with the introduction Tensor Cores in recent years. There are also many newer companies working in this space [2, 3, 4].
My research in this area is in the realm of hardware/algorithmic co-design. Specifically, I am interested in integrating sparsity/quantization/adaptive computation into the design of the hardware. I mainly focus on hardware architectures based around systolic arrays (similar to the TPU).
Relevant Publications
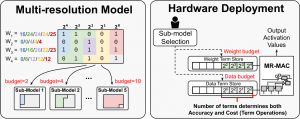
Field-Configurable Multi-resolution Inference: Rethinking Quantization
S. Zhang, B. McDanel, H. T. Kung, X. Dong
26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2021
preprint
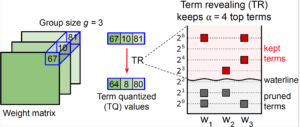
Term Quantization: Furthering Quantization at Run Time
H. T. Kung, B. McDanel, S. Zhang
Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020.
paper
Maestro: A Memory-on-Logic Architecture for Coordinated Parallel Use of Many Systolic Arrays
H. T. Kung, B. McDanel, S. Zhang, X. Dong, C. Chen.
30th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2019
paper
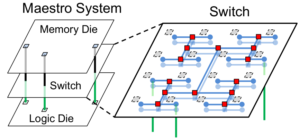
Full-stack Optimization for Accelerating CNNs Using Powers-of-Two Weights with FPGA Validation
B. McDanel, S. Zhang, H. T. Kung, X. Dong.
32nd ACM International Conference on Supercomputing (ICS), 2019
paper
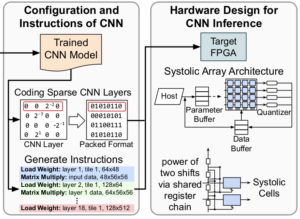
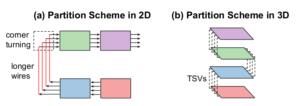
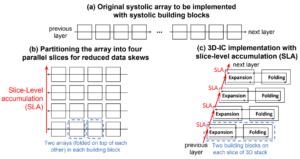
Systolic Building Block for Logic-on-Logic 3D-IC Implementations of Convolutional Neural Networks
H. T. Kung, B. McDanel, S. Zhang, C. T. Wang, J. Cai, C. Y. Chen, V. Chang, M. F. Chen, J. Sun, and D. Yu.
IEEE International Symposium on Circuits and Systems (ISCAS), 2019
paper
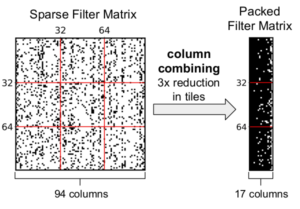
Packing Sparse Convolutional Neural Networks for Efficient Systolic Array Implementations: Column Combining Under Joint Optimization
H. T. Kung, B. McDanel, and S. Zhang
24th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2019
paper | code
Adaptive Tiling: Applying Fixed-size Systolic Arrays To Sparse Convolutional Neural Networks
H. T. Kung, B. McDanel, S. Zhang
International Conference on Pattern Recognition (ICPR), 2018
paper
Mapping Systolic Arrays Onto 3D Circuit Structures: Accelerating Convolutional Neural Network Inference
H. T. Kung, B. McDanel, S. Zhang
IEEE Workshop on Signal Processing Systems (SiPs), 2018.
paper