Quantization of DNNs
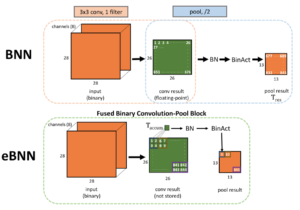
Quantization is an extremely active area in improving the efficiency of DNN inference. Quantization works by reducing the precision of weights and date to make storage and computation more efficient. The potential downside of quantization is a reduction in the performance (e.g., classification accuracy for image classification) of the quantized model.
So far, my research in this area has mainly focused on the deployment aspect of quantization: how can we efficiently use quantized models on real systems? This question has different answers based on the precision of the model (e.g., 1-bit versus 8-bit models) and the hardware the model will be deployed on (e.g., embedded devices, FPGAs, GPUs, etc…).
Relevant Publications
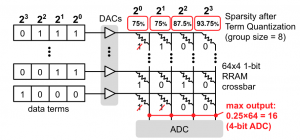
Saturation RRAM Leveraging Bit-level Sparsity Resulting from Term Quantization
B. McDanel, H. T. Kung, S. Zhang
IEEE International Symposium on Circuits and Systems (ISCAS), 2021
paper
Field-Configurable Multi-resolution Inference: Rethinking Quantization
S. Zhang, B. McDanel, H. T. Kung, X. Dong
26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2021
preprint
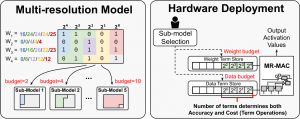
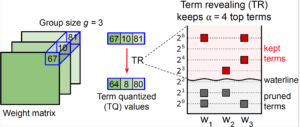
Term Quantization: Furthering Quantization at Run Time
H. T. Kung, B. McDanel, S. Zhang
Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020.
paper
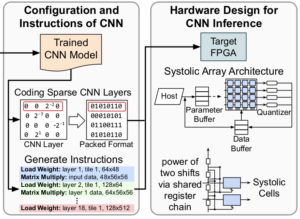
Full-stack Optimization for Accelerating CNNs Using Powers-of-Two Weights with FPGA Validation
B. McDanel, S. Zhang, H. T. Kung, X. Dong.
32nd ACM International Conference on Supercomputing (ICS), 2019
paper